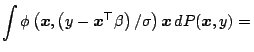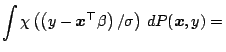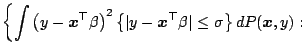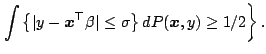



Next: 9.5 Analysis of Variance
Up: 9. Robust Statistics
Previous: 9.3 Location and Scale
Subsections
The linear regression model may be
written in the form
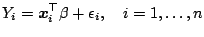 |
(9.101) |
where
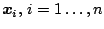 and
and
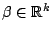 .
The assumptions of the standard model are that the
.
The assumptions of the standard model are that the 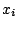 are fixed and
that the
are fixed and
that the
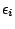 are i.i.d. random variables with the default
distribution being the normal distribution
are i.i.d. random variables with the default
distribution being the normal distribution
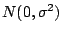 . There are
of course many other models in the literature including random
-values and a covariance structure for the errors
.
For the purpose of robust regression we
consider probability distributions
. There are
of course many other models in the literature including random
-values and a covariance structure for the errors
.
For the purpose of robust regression we
consider probability distributions 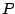 on
on
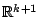 where the
first
where the
first 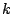 components refer to the covariates
components refer to the covariates
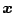 and the last component is the corresponding value of
and the last component is the corresponding value of
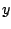 . We restrict attention to the family
. We restrict attention to the family
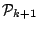 of
probability measures given by
of
probability measures given by
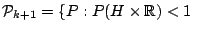 for all lower dimensional subspaces for all lower dimensional subspaces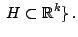 |
(9.102) |
The metric we use on
is
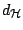 with
with
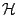 given
by (9.73).
given
by (9.73).
Consider the regression group 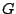 of transformations
of transformations
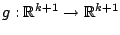 of the form
of the form
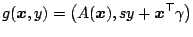 |
(9.103) |
where 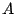 is a non-singular
is a non-singular 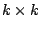 -matrix,
-matrix,
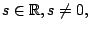 and
and
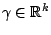 . A functional
. A functional
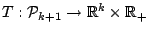 is called a
regression functional if for all
is called a
regression functional if for all 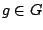 and
and
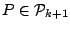
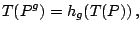 |
(9.104) |
where
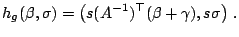 |
(9.105) |
with and 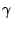 as in (9.103). The first components
of
as in (9.103). The first components
of 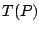 specify the value of
and the last
component that of
specify the value of
and the last
component that of 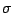 . The restriction to models
of (9.102) is that without such
a restriction there is no uniquely defined value of
. The restriction to models
of (9.102) is that without such
a restriction there is no uniquely defined value of 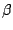 .
.
Given a distribution
we define an
M-functional by
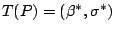 where
where
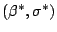 is a solution of the equations
is a solution of the equations
for given functions
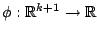 and
and
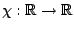 . Just as in
Sect. 9.3.2 for M-functionals of location and scatter there
are
problems concerning the existence and uniqueness. [70] give sufficient conditions for existence which depend
only on the properties of
. Just as in
Sect. 9.3.2 for M-functionals of location and scatter there
are
problems concerning the existence and uniqueness. [70] give sufficient conditions for existence which depend
only on the properties of 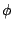 and
and 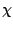 and the values of
and the values of
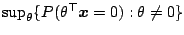 and
and
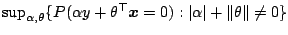 . Uniqueness
requires additional strong assumptions such as either symmetry or the
existence of a density for the conditional distribution of
. Uniqueness
requires additional strong assumptions such as either symmetry or the
existence of a density for the conditional distribution of
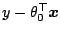 for each fixed
. [58] considers the minimization problem
for each fixed
. [58] considers the minimization problem
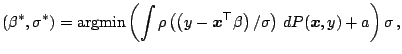 |
(9.108) |
where
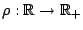 is convex with
is convex with 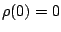 and
and
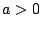 . Under appropriate conditions on
. Under appropriate conditions on 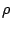 it can be shown
that the solution is unique and that there exists a convergent
algorithm to calculate it. On differentiating (9.108)
we obtain (9.106) and (9.107) with
it can be shown
that the solution is unique and that there exists a convergent
algorithm to calculate it. On differentiating (9.108)
we obtain (9.106) and (9.107) with
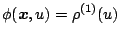 and and 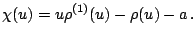 |
(9.109) |
Even if the solution of (9.106) and (9.107)
exists and is unique it is not
necessarily regression equivariant. To make it so we must introduce
a scatter functional
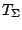 on the marginal distributions
on the marginal distributions
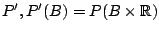 of the covariate
. Such a functional satisfies
of the covariate
. Such a functional satisfies
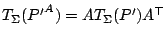 for
any non-singular
-matrix and is required not only for
equivariance reasons but also to downweight outlying
-values or so called leverage points. For this latter
purpose the functional
must also be
robust. We now replace (9.106) by
for
any non-singular
-matrix and is required not only for
equivariance reasons but also to downweight outlying
-values or so called leverage points. For this latter
purpose the functional
must also be
robust. We now replace (9.106) by
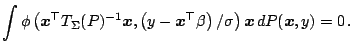 |
(9.110) |
The resulting functional is now regression equivariant but its
analysis is more difficult requiring as it does an analysis of the
robustness properties of the scatter functional
.
Finally we note that in the literature most functions of
(9.106) are of the form
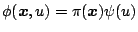 |
(9.111) |
and the resulting functionals are known as GM-functionals. We refer to
[54].
Given a regression functional
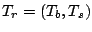 where
where 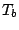 refers to
the -components and
refers to
the -components and 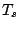 is the scale part it is usual to
define breakdown just by the behaviour of and to neglect .
The breakdown point of
is the scale part it is usual to
define breakdown just by the behaviour of and to neglect .
The breakdown point of 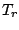 at the
distribution is defined by
at the
distribution is defined by
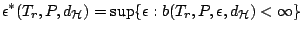 |
(9.112) |
where
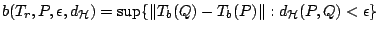 |
(9.113) |
with corresponding definitions for
the gross error neighbourhood
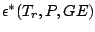 and for the finite sample breakdown point
and for the finite sample breakdown point
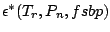 . To state the next theorem we set
. To state the next theorem we set
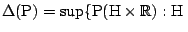 a plane in a plane in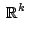 of dimension at most of dimension at most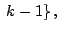 |
|
which is the regression equivalent of (9.77). We have
Theorem 5
For any regression equivariant functional
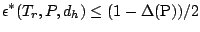 and and 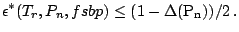 |
(9.114) |
If one considers 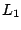 -regression
-regression
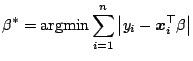 |
(9.115) |
it can be shown if one
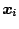 is sufficiently
outlying then the residual at this point will be zero
and hence the finite sample breakdown point is a disappointing
is sufficiently
outlying then the residual at this point will be zero
and hence the finite sample breakdown point is a disappointing 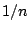 .
This turns out to apply to most M-functionals
of the last section whose breakdown point is at most
.
This turns out to apply to most M-functionals
of the last section whose breakdown point is at most 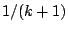 irrespective of their exact definition. The literature on this point
is unsatisfactory. Although some M-functionals have been shown to
have a positive breakdown point this has only been done under the
assumption that the scale part is known. As obtaining the
correct magnitude of the scale of the errors is in some sense the most
difficult problem in robust regression such
results are of limited value. They do not however alter the fact that
M-functionals have a disappointing breakdown point. We now turn to the
problem of constructing high breakdown regression functionals.
irrespective of their exact definition. The literature on this point
is unsatisfactory. Although some M-functionals have been shown to
have a positive breakdown point this has only been done under the
assumption that the scale part is known. As obtaining the
correct magnitude of the scale of the errors is in some sense the most
difficult problem in robust regression such
results are of limited value. They do not however alter the fact that
M-functionals have a disappointing breakdown point. We now turn to the
problem of constructing high breakdown regression functionals.
The first high breakdown regression functional was proposed by [52] and is as follows.
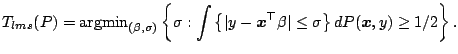 |
(9.116) |
The idea goes back to Tukey's shortest
half-sample of which it is the regression counter part. It can be
shown that it has almost the highest finite sample
breakdown point given by Theorem
5. By slightly altering the factor 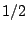 in (9.116) to
take into account the dimension of the
-variables it
can attain
this bound. [88] propagated its use and gave it the name by which it
is now known, the least median
of squares LMS. Rousseeuw calculated the finite sample breakdown
point and provided a first heuristic algorithm which could be
applied to real data sets. He also defined a second high breakdown
functional known as least trimmed
squares LTS defined by
in (9.116) to
take into account the dimension of the
-variables it
can attain
this bound. [88] propagated its use and gave it the name by which it
is now known, the least median
of squares LMS. Rousseeuw calculated the finite sample breakdown
point and provided a first heuristic algorithm which could be
applied to real data sets. He also defined a second high breakdown
functional known as least trimmed
squares LTS defined by
There are now many high breakdown regression functionals such as
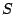 -functionals ([98]), MM-functionals ([114]),
-functionals ([98]), MM-functionals ([114]),
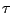 -functionals ([116]), constrained
M-functionals ([75]), rank regression
([17]) and regression depth ([93]). Just as in the location and scale problem in
-functionals ([116]), constrained
M-functionals ([75]), rank regression
([17]) and regression depth ([93]). Just as in the location and scale problem in
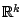 statistical functionals can have the same breakdown points but very
different bias functions. We refer to
[72], [71] and [13]. All these high
breakdown functionals either attain or by some minor adjustment can be made
to attain the breakdown points of Theorem 5 with the exception of
depth based methods where the maximal
breakdown point is
statistical functionals can have the same breakdown points but very
different bias functions. We refer to
[72], [71] and [13]. All these high
breakdown functionals either attain or by some minor adjustment can be made
to attain the breakdown points of Theorem 5 with the exception of
depth based methods where the maximal
breakdown point is 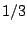 (see [32]).
(see [32]).
All the above high breakdown regressional functionals can be shown to
exist under weak assumptions but just as in the case of high breakdown
location and scatter functionals in
uniqueness can only
be shown under very strong conditions which typically involve the
existence of a density function for the errors (see [25]).
The comments made about high breakdown location and scale
functionals in
apply here. Thus even if a regression
functional is well defined at some particular model there will be
other models arbitrarily close in the metric
where
a unique solution does not exist. This points to an inherent local
instability of high breakdown regression functionals which has been
noted in the literature
([100,36]).
[30] has constructed regression functionals
which are well defined at all models with
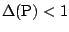 and which
are locally uniformly Lipschitz, not however locally uniformly Fréchet
differentiable. For this reason all confidence regions and efficiency
claims must be treated with a degree of caution. An increase in
stability can however be attained by using the LTS-functional instead of the
LMS-functional, by reweighting the observations or using some form of
one-step M-functional improvement as in (9.29).
and which
are locally uniformly Lipschitz, not however locally uniformly Fréchet
differentiable. For this reason all confidence regions and efficiency
claims must be treated with a degree of caution. An increase in
stability can however be attained by using the LTS-functional instead of the
LMS-functional, by reweighting the observations or using some form of
one-step M-functional improvement as in (9.29).
Just as with high breakdown location and scatter functionals in
the calculation
of high breakdown regression functionals poses considerable
difficulties. The first high breakdown regression functional was
Hampel's least median of squares and even in the simplest case of
a straight line in
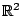 the computational cost is of order
the computational cost is of order
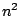 . The algorithm is by no means simple requiring as it
does ideas from computational geometry (see [35]).
From this and the fact that the computational
complexity increases with dimension it follows that one has to fall back on
heuristic algorithms. The one recommended for linear regression is
that of [95] for the LTS-functional.
. The algorithm is by no means simple requiring as it
does ideas from computational geometry (see [35]).
From this and the fact that the computational
complexity increases with dimension it follows that one has to fall back on
heuristic algorithms. The one recommended for linear regression is
that of [95] for the LTS-functional.
To apply the concept of
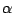 -outlier regions to the linear regression model we have to
specify the distribution
-outlier regions to the linear regression model we have to
specify the distribution 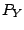 of the response and the joint
distribution
of the response and the joint
distribution
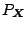 of the regressors assuming them to
be random. For specificness we consider the model
of the regressors assuming them to
be random. For specificness we consider the model
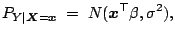 |
(9.118) |
and
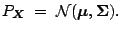 |
(9.119) |
Assumption (9.118) states that the conditional
distribution of the response given the regressors is normal and
assumption (9.119) means that the joint distribution of
the regressors is a certain 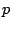 -variate normal distribution. If both
assumptions are fulfilled then the joint distribution of
-variate normal distribution. If both
assumptions are fulfilled then the joint distribution of
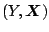 is a multivariate normal distribution.
is a multivariate normal distribution.
We can define outlier regions under model (9.101) in several
reasonable ways. If only (9.118) is assumed then
a response--outlier region could be defined as
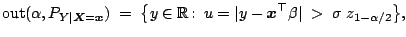 |
(9.120) |
which is appropriate if the regressors are fixed and only outliers in
-direction are to be identified. If the regressors are random,
which will be the more frequent case in actuarial or econometric
applications, outliers in
-direction are important as
well. Under assumption (9.119)
a regressor--outlier region is a special case of the
-outlier region (9.99). This approach leads to
a population based version of the concept of
leverage points. These are the points in a sample
 from model (9.101) ''for
which
is far away
from the bulk of the
in the data'' ([97]).
from model (9.101) ''for
which
is far away
from the bulk of the
in the data'' ([97]).
For the identification of regressor-outliers
(leverage points) the same identification rules
can be applied as in the multivariate normal situation. For the
detection of response-outliers by
resistant one-step identifiers,
one needs robust estimators of the regression coefficients and the
scale . Examples of high breakdown estimators that can be used
in this context are the
Least Trimmed Squares estimator and
the corresponding scale estimator
([88,94]),
S-estimators ([98]),
MM-estimators ([114]) or the REWLS-estimators
([47]).
Next: 9.5 Analysis of Variance
Up: 9. Robust Statistics
Previous: 9.3 Location and Scale