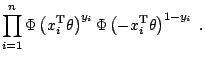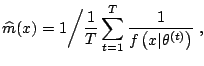The natural approach to these computational problems is to use
computer simulation and Monte Carlo techniques, rather than numerical
methods, simply because there is much more to gain from exploiting the
probabilistic properties of the integrands rather than their
analytical properties. In addition, the dimension of most problems
considered in current Bayesian Statistics is such that very involved
numerical methods should be used to provide a satisfactory
approximation in such integration or optimisation problems. Indeed,
down-the-shelf numerical methods cannot handle integrals in dimensions
larger than ![]() and more advanced numerical integration methods
require analytical studies on the distribution of interest.
and more advanced numerical integration methods
require analytical studies on the distribution of interest.
Given the statistical nature of the problem, the approximation of an integral like
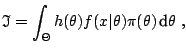 |
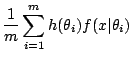 |
![$\displaystyle \mathbb{E}^{\pi} [h(\theta)\vert x] = \frac{\int_{\Theta} h(\thet...
...\text{d}}\theta} {\int_{\Theta} f(x\vert\theta) \pi(\theta) \,{\text{d}}\theta}$](img6190.gif) |
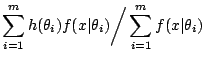 |
In addition, if the posterior variance
var![]() is
finite, the Central Limit Theorem applies to the empirical
average (11.4), which is then asymptotically normal
with variance
var
is
finite, the Central Limit Theorem applies to the empirical
average (11.4), which is then asymptotically normal
with variance
var![]() . Confidence regions can
then be built from this normal approximation and, most importantly,
the magnitude of the error remains of order
. Confidence regions can
then be built from this normal approximation and, most importantly,
the magnitude of the error remains of order ![]() , whatever the
dimension of the problem, in opposition with numerical
methods.11.5 (See also [37],
Chap. 4, for more details on the convergence assessment based on the
CLT.)
, whatever the
dimension of the problem, in opposition with numerical
methods.11.5 (See also [37],
Chap. 4, for more details on the convergence assessment based on the
CLT.)
The Monte Carlo method actually applies in a much wider generality
than the above simulation from ![]() . For instance, because
. For instance, because
![]() can be represented in an infinity of ways as an
expectation, there is no need to simulate from the distributions
can be represented in an infinity of ways as an
expectation, there is no need to simulate from the distributions
![]() or
or ![]() to get a good approximation
of
to get a good approximation
of
![]() . Indeed, if
. Indeed, if ![]() is a probability density with
supp
is a probability density with
supp![]() including the support of
including the support of
![]() , the integral
, the integral
![]() can also be represented as
an expectation against
can also be represented as
an expectation against ![]() , namely
, namely
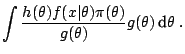 |
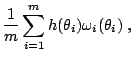 |
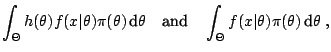 |
While this convergence is guaranteed for all densities ![]() with wide
enough support, the choice of the importance function
is crucial. First, simulation from
with wide
enough support, the choice of the importance function
is crucial. First, simulation from ![]() must be easily implemented.
Moreover, the function
must be easily implemented.
Moreover, the function ![]() must be close enough to the
function
must be close enough to the
function
![]() , in order to reduce the variability
of (11.5) as much as possible; otherwise, most of the weights
, in order to reduce the variability
of (11.5) as much as possible; otherwise, most of the weights
![]() will be quite small and a few will be overly
influential. In fact, if
will be quite small and a few will be overly
influential. In fact, if
![]() is not finite, the variance of the estimator (11.5) is
infinite (see [37], Chap. 3).
Obviously, the dependence on
is not finite, the variance of the estimator (11.5) is
infinite (see [37], Chap. 3).
Obviously, the dependence on ![]() of the importance function
of the importance function ![]() can be
avoided by proposing generic choices such as the posterior
distribution
can be
avoided by proposing generic choices such as the posterior
distribution
![]() .
.
In either point estimation or simple testing situations, the computational problem is often expressed as a ratio of integrals. Let us start with a toy example to set up the way Monte Carlo methods proceed and highlight the difficulties of applying a generic approach to the problem.
If the inferential
problem is to decide about the value of ![]() , the posterior
expectation is
, the posterior
expectation is
![$\displaystyle \mathbb{E}^{\pi} [\theta\vert x_1,\ldots,x_n] = \int \theta \prod_{i=1}^n \left[ \nu + (x_i-\theta)^2 \right]^{-(\nu+1)/2} \,{\text{d}}\theta$](img6212.gif) |
||
![$\displaystyle \qquad \bigg/ \int \prod_{i=1}^n \left[ \nu + (x_i-\theta)^2 \right]^{-(\nu+1)/2} \,{\text{d}}\theta\;.$](img6213.gif) |
Now, there is a clear arbitrariness in the choice of ![]() in the
sample
in the
sample
![]() for the proposal
for the proposal
![]() . While any of the
. While any of the ![]() 's has the same
theoretical validity to ''represent'' the integral and the
integrating density, the choice of
's has the same
theoretical validity to ''represent'' the integral and the
integrating density, the choice of ![]() 's closer to the posterior
mode (the true value of
's closer to the posterior
mode (the true value of ![]() is 0) induces less variability in
the estimates, as shown by a further simulation experiment through
Fig. 11.4. It is fairly clear from this comparison that the
choice of extremal values like
is 0) induces less variability in
the estimates, as shown by a further simulation experiment through
Fig. 11.4. It is fairly clear from this comparison that the
choice of extremal values like
![]() and even more
and even more
![]() is detrimental to the quality of the
approximation, compared with the median
is detrimental to the quality of the
approximation, compared with the median
![]() . The
range of the estimators is much wider for both extremes, but the
influence of this choice is also visible for the average which does
not converge so quickly.11.7
. The
range of the estimators is much wider for both extremes, but the
influence of this choice is also visible for the average which does
not converge so quickly.11.7
![\includegraphics[width=9cm]{text/3-11/toy2_1.eps}](img6229.gif)
|
![\includegraphics[width=\textwidth]{text/3-11/regrange.eps}](img6230.gif)
|
to12cm![\includegraphics[width=3.7cm]{text/3-11/toy2_10.eps}](img6231.gif)
![\includegraphics[width=3.7cm]{text/3-11/toy2_1.eps}](img6232.gif)
![\includegraphics[width=3.7cm]{text/3-11/toy2_6.eps}](img6233.gif) |
This example thus shows that Monte Carlo methods, while widely
available, may easily face inefficiency problems when the simulated
values are not sufficiently attuned to the distribution of
interest. It also shows that, fundamentally, there is no difference
between importance sampling and regular Monte Carlo, in that the
integral
![]() can naturally be represented in many ways.
can naturally be represented in many ways.
Although we do not wish to spend too much space on this issue, let us
note that the choice of the importance function gets paramount when
the support of the function of interest is not the whole
space. For instance, a tail probability, associated with
![]() say, should be estimated with an
importance function whose support is
say, should be estimated with an
importance function whose support is
![]() . (See
[37], Chap. 3, for details.)
. (See
[37], Chap. 3, for details.)
![\includegraphics[width=9.5cm]{text/3-11/toy4_1.eps}](img6245.gif)
|
The above example is one-dimensional (in the parameter) and the
problems exhibited there can be found severalfold in multidimensional
settings. Indeed, while Monte Carlo methods do not suffer from the
''curse of dimension''
in the sense that the error of the
corresponding estimators is always decreasing in ![]() ,
notwithstanding the dimension, it gets increasingly difficult to come
up with satisfactory importance sampling distributions as the
dimension gets higher and higher. As we will see in
Sect. 11.5, the intuition built on MCMC methods has to be
exploited to derive satisfactory importance
functions.
,
notwithstanding the dimension, it gets increasingly difficult to come
up with satisfactory importance sampling distributions as the
dimension gets higher and higher. As we will see in
Sect. 11.5, the intuition built on MCMC methods has to be
exploited to derive satisfactory importance
functions.
![\includegraphics[width=11.7cm,clip]{text/3-11/polydim1.eps}](img6247.gif) |
| Pr |
Figure 11.6 illustrates this degeneracy of the importance
sampling
approach as the dimension increases. We simulate parameters ![]() 's
and datasets
's
and datasets ![]()
![]() for dimensions
for dimensions ![]() ranging
from
ranging
from ![]() to
to ![]() , then represented the histograms of the largest
weight for
, then represented the histograms of the largest
weight for
![]() . The
. The ![]() 's were simulated from
a
's were simulated from
a
![]() distribution, while the importance sampling
distribution was a
distribution, while the importance sampling
distribution was a
![]() distribution.
distribution.
As explained in Sects. 11.2.2 and 11.2.3, the first computational difficulty associated with Bayesian testing is the derivation of the Bayes factor, of the form
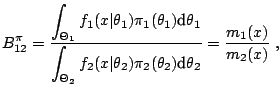 |
Specific Monte Carlo methods for the estimation of ratios of
normalizing constants,
or, equivalently, of Bayes factors, have been developed in the past
five years. See Chen et al. (2000,
Chap. 5) for a complete exposition. In
particular, the importance sampling technique is rather well-adapted
to the computation of those
Bayes factors: Given a importance distribution, with density
proportional to ![]() , and a sample
, and a sample
![]() simulated from
simulated from ![]() , the marginal density for model
, the marginal density for model
![]() ,
,
![]() , is approximated by
, is approximated by
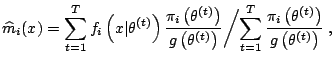 |
 |
 |
However, the variance of
![]() may be infinite, depending
on the choice of
may be infinite, depending
on the choice of ![]() . A possible choice is
. A possible choice is
![]() ,
with wider tails than
,
with wider tails than
![]() , but this is often inefficient
if the data is informative because the prior and the posterior
distributions will be quite different and most of the simulated values
, but this is often inefficient
if the data is informative because the prior and the posterior
distributions will be quite different and most of the simulated values
![]() fall outside the modal region of the likelihood. For
the choice
fall outside the modal region of the likelihood. For
the choice
![]() ,
,
![$\displaystyle \frac{c_2}{c_1} = \frac{\mathbb{E}^{\pi_2} \left[{\tilde\pi}_1(\t...
...ight]} {\mathbb{E}^{\pi_1}\left[{\tilde\pi}_2(\theta\vert x)\,h(\theta)\right]}$](img6282.gif) |
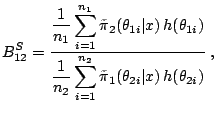 |
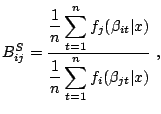 |
As can be seen from the previous developments, such methods require a rather careful tuning to be of any use. Therefore, they are rather difficult to employ outside settings where pairs of models are opposed. In other words, they cannot be directly used in general model choice settings where the parameter space (and in particular the parameter dimension) varies across models, like, for instance, Example 7. To address the computational issues corresponding to these cases requires more advanced techniques introduced in the next section.
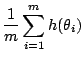
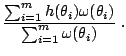
![$\displaystyle =\sum_{j=1}^m \theta_j \prod_{i=2}^n \left[ \nu + (x_i-\theta_j)^2 \right]^{-(\nu+1)/2}$](img6218.gif)
![$\displaystyle \qquad \bigg/ \sum_{j=1}^m \prod_{i=2}^n \left[ \nu + (x_i-\theta_j)^2 \right]^{-(\nu+1)/2}$](img6219.gif)
![\includegraphics[width=9cm]{text/3-11/toy1.eps}](img6228.gif)
![$\displaystyle =\sum_{j=1}^m \prod_{i\ne k} \left[ \nu + (x_i-\vert\theta_j\vert)^2 \right]^{-(\nu+1)/2}\Big/ \psi_k(\vert\theta_j\vert)$](img6242.gif)
![$\displaystyle \qquad \bigg/ \sum_{j=1}^m \prod_{i\ne k} \left[ \nu + (x_i-\theta_j)^2 \right]^{-(\nu+1)/2}\;,$](img6243.gif)