The purpose of this section is to present a
comparative study of the three most commonly used and easy-to-implement
smoothers: the kernel, the ![]() -nearest neighbor and the cubic spline
smoothers.
The comparison is performed theoretically and empirically. The
practical comparison is based on a simulated data set, which is presented in
Table 2 in Appendix 2.
-nearest neighbor and the cubic spline
smoothers.
The comparison is performed theoretically and empirically. The
practical comparison is based on a simulated data set, which is presented in
Table 2 in Appendix 2.
The theoretical comparison is presented for the two design models -
fixed equidistant and random design. Kernel
estimators ![]() with weight functions
with weight functions
![]() and
and
![]() (see Section 3.1) and the
(see Section 3.1) and the ![]() -
-![]() smoother
smoother ![]() are
compared.
Although the spline estimator also
makes sense for stochastic predictor variables its statistical properties
have been studied mostly for the fixed design case. We have found in Section
3.6 that
the fixed design spline almost
acts like a kernel smoother with design dependent bandwidth.
Recall the kernel-spline equivalence theorem,
Theorem 3.6.1 It says that the spline estimator
are
compared.
Although the spline estimator also
makes sense for stochastic predictor variables its statistical properties
have been studied mostly for the fixed design case. We have found in Section
3.6 that
the fixed design spline almost
acts like a kernel smoother with design dependent bandwidth.
Recall the kernel-spline equivalence theorem,
Theorem 3.6.1 It says that the spline estimator
![]() for regularly distributed
for regularly distributed
![]() behaves like a Priestley-Chao kernel smoother with
effective local bandwidth
behaves like a Priestley-Chao kernel smoother with
effective local bandwidth

From Table 3.1 we saw that the ![]() -
-![]() estimator
estimator ![]() has mean squared error properties comparable to the kernel estimator if the
bandwidth
has mean squared error properties comparable to the kernel estimator if the
bandwidth
![]() It therefore makes
sense to consider kernel smoothers with bandwidths proportional to
It therefore makes
sense to consider kernel smoothers with bandwidths proportional to
![]()
Bias and variance behaviors of kernel
smoothers with weigths
![]() and bandwidth
and bandwidth
![]() have been studied by
Jennen-Steinmetz and Gasser (1988). The bias and variance of
the above three estimators for the fixed equidistant design
have been studied by
Jennen-Steinmetz and Gasser (1988). The bias and variance of
the above three estimators for the fixed equidistant design
![]() are listed in Table 3.2.
For the correct interpretation of this table recall the definition of
are listed in Table 3.2.
For the correct interpretation of this table recall the definition of
![]() as given in Section 3.1. Table 3.2
shows clearly that the
two kernel sequences
as given in Section 3.1. Table 3.2
shows clearly that the
two kernel sequences
![]() and
and ![]() have the same
mean squared error properties for the fixed equidistant design case. As noted
before the
have the same
mean squared error properties for the fixed equidistant design case. As noted
before the ![]() -
-![]() weight sequence can be seen as a kernel sequence if we make
the identification
weight sequence can be seen as a kernel sequence if we make
the identification
![]() .
.
| bias | variance | |
| kernel weights |
|
|
| kernel weights
|
|
|
| k-NN weights |
|
|
The bias and variance for the random design case
is drastically different, as Table 3.3 shows. Pointwise bias and variance
are complicated functionals not only of the regression curve
![]() but also of the marginal density
but also of the marginal density ![]() .
.
| bias | variance | |
| kernel weights |
|
|
| kernel weights
|
|
|
| k-NN weights |
|
|
Note that essentially all three estimators coincide for the fixed design case
when chosing ![]() as indicated already in Section 3.4.
This is not true
for the random design.
For
as indicated already in Section 3.4.
This is not true
for the random design.
For ![]() the variance of the kernel with
weights
the variance of the kernel with
weights
![]() is twice as big as for the Nadaraya-Watson
estimator.
By constrast, the bias of the Nadaraya-Watson smoother is a
complicated expression of
is twice as big as for the Nadaraya-Watson
estimator.
By constrast, the bias of the Nadaraya-Watson smoother is a
complicated expression of ![]() and
and ![]() .
The same is true when comparing the
bias of the
.
The same is true when comparing the
bias of the ![]() -
-![]() smoother for
smoother for ![]() .
.
The empirical study is based on the simulated data from Figure
3.20. It shows ![]() data points simulated from the regression
curve
data points simulated from the regression
curve
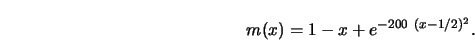
A list of the values
![\includegraphics[scale=0.7]{ANRsimkernel.ps}](anrhtmlimg798.gif)
|
The kernel weights

Special
attention must be paid to the boundary points 0 and 1 of the observation
interval. Estimation points ![]() that are close to the boundary have only
a one-sided neighborhood over which to average the
that are close to the boundary have only
a one-sided neighborhood over which to average the ![]() -values.
The
kernel smoother must therefore be less accurate at the boundary (see
Section 4.4 for a mathematical formulation of this problem).
This
inaccuracy can be seen from Figure 3.21 near the left boundary: most of
the observations there lie below the true regression curve, the
asymmetric average therefore considerably underestimates the true
-values.
The
kernel smoother must therefore be less accurate at the boundary (see
Section 4.4 for a mathematical formulation of this problem).
This
inaccuracy can be seen from Figure 3.21 near the left boundary: most of
the observations there lie below the true regression curve, the
asymmetric average therefore considerably underestimates the true ![]() near
near ![]() .
.
The bandwidth ![]() was chosen completely
subjectively. I asked several colleagues and they
felt that a higher amount of smoothing would ``wash out"
too much structure and a smaller bandwidth would give too rough a curve.
Had another kernel been used, for instance a kernel with compact
support, the picture would have been different for this specific bandwidth of
was chosen completely
subjectively. I asked several colleagues and they
felt that a higher amount of smoothing would ``wash out"
too much structure and a smaller bandwidth would give too rough a curve.
Had another kernel been used, for instance a kernel with compact
support, the picture would have been different for this specific bandwidth of
![]() .
The reason is that different kernels are in general
differently scaled. A way of adjusting the bandwidths and
kernels to the same scale is discussed in Section 5.4.
.
The reason is that different kernels are in general
differently scaled. A way of adjusting the bandwidths and
kernels to the same scale is discussed in Section 5.4.
The ![]() -
-![]() estimate produced a slightly rougher curve.
In Figure 3.22
the graph of the
estimate produced a slightly rougher curve.
In Figure 3.22
the graph of the ![]() -
-![]() smoother, as defined in (3.4.19), is displayed
for
smoother, as defined in (3.4.19), is displayed
for ![]() The reason for the ``wiggliness" is the so-called uniform
weight sequence that is used in (3.4.19). Theoretically speaking, the
The reason for the ``wiggliness" is the so-called uniform
weight sequence that is used in (3.4.19). Theoretically speaking, the
![]() -
-![]() smooth is a discontinuous function.
smooth is a discontinuous function.
![\includegraphics[scale=0.7]{ANRsimknn.ps}](anrhtmlimg806.gif)
|
In practice, this means that as the window of weights moves
over the observation interval, new observations enter at the boundary of
the ``uniform window" according to the nearest neighbor rule. Any
entering observation that has a value different from the current average
will cause an abrupt change of the ![]() -
-![]() smoother.
Such an
effect would be diminished if a smoother
smoother.
Such an
effect would be diminished if a smoother ![]() -
-![]() weight sequence, like
the one defined in (3.4.19), were used.
weight sequence, like
the one defined in (3.4.19), were used.
Here also boundary effects need special discussion. As the
estimation point ![]() moves to the boundary, the interval of observations
entering the determination of the smoother becomes
asymmetric.
This was also the
case for the kernel smoothers.
Note, however, that, in contrast to kernel
smoothing, the asymmetric region left or right of
moves to the boundary, the interval of observations
entering the determination of the smoother becomes
asymmetric.
This was also the
case for the kernel smoothers.
Note, however, that, in contrast to kernel
smoothing, the asymmetric region left or right of ![]() always has the
same number of points.
The averaging procedure near the boundary thus
involves a lot more points which, in general, have different mean values.
This
is not so drastic in our example since the regression curve is relatively
flat at the boundaries.
In cases where the regression function is steeper
at the boundary the
always has the
same number of points.
The averaging procedure near the boundary thus
involves a lot more points which, in general, have different mean values.
This
is not so drastic in our example since the regression curve is relatively
flat at the boundaries.
In cases where the regression function is steeper
at the boundary the ![]() -
-![]() smoother is expected to be more biased than
the kernel smoother.
smoother is expected to be more biased than
the kernel smoother.
The smoothing parameter ![]() was also chosen
subjectively here.
A bigger
was also chosen
subjectively here.
A bigger ![]() seemed to me to yield too smooth a curve
compared to the raw observations.
A smaller
seemed to me to yield too smooth a curve
compared to the raw observations.
A smaller ![]() produced too rough a
curve, and amplified local spiky structures such as the one at
produced too rough a
curve, and amplified local spiky structures such as the one at
![]() .
.
The spline smoother
![]() is shown in Figure 3.23.
The algorithm of Reinsch (1967)
was used to generate the smooth
is shown in Figure 3.23.
The algorithm of Reinsch (1967)
was used to generate the smooth
![]() .
The smoothing parameter was chosen to be
.
The smoothing parameter was chosen to be ![]() ; that is,
; that is,
![]() is the solution to the minimization problem
is the solution to the minimization problem
![\begin{displaymath}\int [g''(x)]^2 dx = \min!\end{displaymath}](anrhtmlimg810.gif)

In Table 3.4 the relation between ![]() and
and
![]() is shown.
As
is shown.
As ![]() increases the spline
curve becomes flatter and flatter.
In the limit it is equivalent
to fitting a least squares line.
increases the spline
curve becomes flatter and flatter.
In the limit it is equivalent
to fitting a least squares line.
![\includegraphics[scale=0.7]{ANRsimspline.ps}](anrhtmlimg815.gif)
|
Table 3.5 presents the equivalent parameter ![]() for various
values of
for various
values of ![]() The
The ![]() equivalent to
equivalent to ![]() is
therefore
is
therefore
![]() .
.
By construction, the spline fit looks very smooth since it is a function
that is glued together from pieces of cubic polynomials.
The overall
shape of the spline function is the same that as for the kernel and
![]() -
-![]() smooth.
The peak in the middle of the observation interval is relatively well
approximated (Figure 3.24), but to the left of it all smoothers exhibit a
somewhat smaller bump that is really only a random function
of the data pattern.
smooth.
The peak in the middle of the observation interval is relatively well
approximated (Figure 3.24), but to the left of it all smoothers exhibit a
somewhat smaller bump that is really only a random function
of the data pattern.
Note that the spline smoother may produce a partially negative smooth even
when all the response variables are positive.
This can be understood from the asymptotic
kernel representation (3.6.35) of
![]() .
Since the kernel
.
Since the kernel
![]() has negative side lobes (Figure 3.10) it may happen that for a
sparse data pattern the resulting spline smooth is negative although one
averages over purely positive observations.
has negative side lobes (Figure 3.10) it may happen that for a
sparse data pattern the resulting spline smooth is negative although one
averages over purely positive observations.
A comparison of the behavior of all three smoothers can be obtained
from Figure 3.24, the residual curves (``fit" minus ``true") for the three
approximation methods.
All three smoothers have the artificial bump at ![]() ,
introduced by the data pattern, but show essentially the same behavior in
the residual curves.
,
introduced by the data pattern, but show essentially the same behavior in
the residual curves.
![\includegraphics[scale=0.7]{ANRsimresidual.ps}](anrhtmlimg861.gif)
|
Exercises
3.11.1Try the kernel, ![]() -
-![]() and spline smoothing on the simulated data set
with different smoothing parameters. Describe how you found a ``good"
smoothing parameter.
and spline smoothing on the simulated data set
with different smoothing parameters. Describe how you found a ``good"
smoothing parameter.
3.11.2Quantify the behavior of the above smoothers at the boundary of the
observation interval. Supppose
![]() is relatively large at the
boundary. What do you expect from a local averaging method in this
situation?
is relatively large at the
boundary. What do you expect from a local averaging method in this
situation?
In the simulated data set from Table 2
no repeated observations (in the ![]() -variable) have been observed.
For the case of repeated observations the spline smoothing
algorithm of Reinsch (1967) needs some preparatory steps. If one observes
multiple responses for a fixed
-variable) have been observed.
For the case of repeated observations the spline smoothing
algorithm of Reinsch (1967) needs some preparatory steps. If one observes
multiple responses for a fixed ![]() one pools the corresponding
one pools the corresponding
![]() -values into one observation by averaging them. Suppose that there are
-values into one observation by averaging them. Suppose that there are
![]() observations at each
observations at each ![]() .
Then the spline algorithm solves the weighted minimization problem
.
Then the spline algorithm solves the weighted minimization problem
![\begin{displaymath}\sum^n_{i=1} (Y_i - g(X_i))^2 / N_i+ \lambda \int [g''(x)]^2 dx.\end{displaymath}](anrhtmlimg864.gif)
![\includegraphics[scale=0.7]{ANRsimul.ps}](anrhtmlimg792.gif)