It was, of course, fully recognized that the estimate might differ from the parameter in any particular case, and hence that there was a margin of uncertainty. The extent of this uncertainty was expressed in terms of the sampling variance of the estimator.
Sir M. Kendall and A. Stuart (1979, p. 109)
If the smoothing parameter is chosen as a suitable function of the
sample size ![]() , all of the above smoothers converge to the true curve if the
number of observations increases. Of course, the convergence of an estimator is
not enough, as Kendall and Stuart in the above citation say. One is always
interested in the extent of the uncertainty or at what speed the convergence
actually happens. Kendall and Stuart (1979) aptly describe the procedure of
assessing measures of accuracy for classical parametric statistics: The extent
of the uncertainty is expressed in terms of the sampling variance of the
estimator which usually tends to zero at the speed of the square root of the
sample size
, all of the above smoothers converge to the true curve if the
number of observations increases. Of course, the convergence of an estimator is
not enough, as Kendall and Stuart in the above citation say. One is always
interested in the extent of the uncertainty or at what speed the convergence
actually happens. Kendall and Stuart (1979) aptly describe the procedure of
assessing measures of accuracy for classical parametric statistics: The extent
of the uncertainty is expressed in terms of the sampling variance of the
estimator which usually tends to zero at the speed of the square root of the
sample size ![]() .
.
In contrast to this is the nonparametric smoothing situation: The variance alone does not fully quantify the convergence of curve estimators. There is also a bias present which is a typical situation in the context of smoothing techniques. This is the deeper reason why up to this Section the precision has been measured in terms of pointwise mean squared error (MSE), the sum of variance and squared bias. The variance alone doesn't tell us the whole story if the estimator is biased.
We have seen, for instance, in Section 3.4 , that the pointwise MSE
![\begin{displaymath}E [{\hat{m}}(x)-m(x) ]^2,\end{displaymath}](anrhtmlimg865.gif)
A variety of ``global'' distance measures can be defined. For instance, the
integrated absolute deviation (weighted by the marginal density ![]() )
)
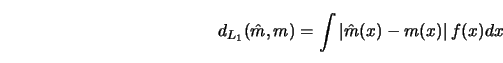
Another distance is defined through the maximal absolute deviation,
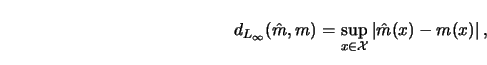
Quadratic measures of accuracy have received the most attention. A typical
representative is the Integrated Squared Error (ISE)
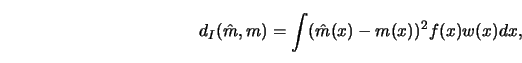
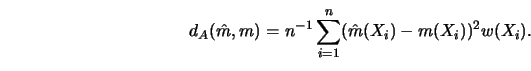
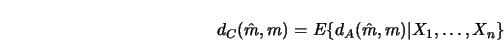

In order to simplify the presentation I will henceforth consider only kernel estimators. Most of the error calculations done for kernel smoothers in Section 3.1 can be extended in a straightforward way to show that kernel smoothers converge in the above global measure of accuracy to the true curve. But apart from such desirable convergence properties, it is important both from a practical and a theoretical point of view to exactly quantify the speed of convergence over a class of functions. This is the subject of the next section. In Section 4.2 pointwise confidence intervals are constructed. Global variability bands and error bars are presented in Section 4.3. The boundary problem, for example, the fact that the smoother behaves qualitatively different at the boundary is discussed in Section 4.4. The selection of kernel functions is presented in Section 4.5. Bias reduction techniques by the jackknife method are investigated in Section 4.6.