The volatility of an asset is a measure of variability of its returns. Traditionally, volatility is measured on past prices of the underlying asset, known as historical volatility. However for investors, who have a high regard for the 'wisdom' of the market, the best estimate of volatility comes from the market itself.
If the market price of the option is taken to be the correct price, then the volatility implied by the market price reflects the market's opinion of what the volatility should be. The value of the volatility of the underlying asset that would equate the option price to its fair value, is called implied volatility. In other words, implied volatility is the volatility, which is implicitly contained in the option price (Alexander; 1996, pp. 14). It is a timely measure - it reflects the market's perceptions today - and it should therefore provide the market's best estimate of future volatility (Jorion; 2001). This is therefore one reason to believe that option-based forecasts can be superior to historical estimates. Supporting evidence on this point is for example provided in Jorion (1995) and Campa and Chang (1998).
Implied volatilities are a useful tool in monitoring the market's opinion regarding the volatility of a particular stock. Besides this, options are often traded on volatility with the implied volatility becoming the effective price of the option. Implied volatility also has important implications for risk management. If volatility increases, so will the value at risk (VaR). Investors may want to adjust their portfolio in order to reduce their exposure to those instruments, whose volatility is predicted to increase. Hence, in a delta hedged portfolio the vega risk (see subsection 11.4.4) can become the most significant risk factor within the portfolio.
When an explicit analytic option pricing formula is available, as
for instance the Black-Scholes formula (11.10), the quoted
price of the option along with known variables, such as the price
of the underlying asset ![]() , the exercise price
, the exercise price ![]() ,
time to expiration
,
time to expiration
![]() and the interest rate
and the interest rate ![]() can
be used in an implicit formula to calculate the so called implied
volatility. The Black-Scholes implied volatility refers to the
market price of the option equal to the price given by the
Black-Scholes formula (11.10). For a call option, it can be
written as
can
be used in an implicit formula to calculate the so called implied
volatility. The Black-Scholes implied volatility refers to the
market price of the option equal to the price given by the
Black-Scholes formula (11.10). For a call option, it can be
written as
where
![]() is the Black-Scholes call
price,
is the Black-Scholes call
price,
![]() is the implied volatility and
is the implied volatility and
![]() is the market price of the call at time instant
is the market price of the call at time instant
![]() . The implied volatility of a European put with the same
strike and maturity can be derived from the put-call parity
(11.18). The existence of the uniqueness of the implied
volatility in (11.64), is due to the fact that the value
of a call option as a function of volatility is a monotonic
mapping from
. The implied volatility of a European put with the same
strike and maturity can be derived from the put-call parity
(11.18). The existence of the uniqueness of the implied
volatility in (11.64), is due to the fact that the value
of a call option as a function of volatility is a monotonic
mapping from
![]() to
to
![]() .
.
The Black-Scholes model assumes that the underlying asset follows
a Brownian motion with constant volatility. If this model is
correct, then the distribution of the underlying asset at any
option expiration is lognormal, and all options on the underlying
asset must have the same implied volatility. Since the market
crash in 1987, the market implied volatilities for index options
have shown that at-the-money options yield lower volatilities than
in-the-money or out-of-the-money options. The convex shape of the
implied volatility with respect to the moneyness (![]() ) is
referred to as the smile effect. The smile effect occurs as
at-the-money options are more sensitive to volatility, so that a
smaller volatility spread is required for them to achieve the same
profit or risk premium as out-of-the-money options.
) is
referred to as the smile effect. The smile effect occurs as
at-the-money options are more sensitive to volatility, so that a
smaller volatility spread is required for them to achieve the same
profit or risk premium as out-of-the-money options.
Jarrow and Rudd (1982) argued that this smile effect can be
partially explained by departures from lognormality in the
underlying asset price, particulary for out-of-the-money options.
The smile is particularly noticeable in the Black-Scholes implied
volatility - possibly because of the inappropriate assumptions
underlying the Black-Scholes model - and tends to increase as the
option approaches expiration (Hull and White; 1987). Hence, the value of
the implied volatility depends on time to expiration ![]() and
strike
and
strike ![]() . The function
. The function
| (11.65) |
is called the implied volatility surface at date ![]() , i.e. it
is the plot of implied volatility across strike and time to
maturity. Using the moneyness of the option,
, i.e. it
is the plot of implied volatility across strike and time to
maturity. Using the moneyness of the option, ![]() , the
implied volatility surface can be represented as a function of
moneyness and of time to expiration. This graphical representation
is convenient, because there is usually a range for moneyness
around
, the
implied volatility surface can be represented as a function of
moneyness and of time to expiration. This graphical representation
is convenient, because there is usually a range for moneyness
around ![]() , where options are liquid and therefore empirical
data is available (Cont and da Fonseca; 2002). The quantlet
, where options are liquid and therefore empirical
data is available (Cont and da Fonseca; 2002). The quantlet
 volsurf
in
XploRe
offers the choice to plot the implied volatiliy surface
either as a function of
volsurf
in
XploRe
offers the choice to plot the implied volatiliy surface
either as a function of ![]() or of
or of ![]() .
.
The dependence of implied volatility on strike and maturity is analyzed by various authors for different markets. It is empirically found that the implied volatility surface exhibits a non-flat profile with respect to both strike and term structure, which contradicts the flat profile provided by the Black-Scholes model. Evidence of this is given for example in Dumas et al. (1996), Fengler et al. (2001), Franks and Schwarz (1991), Heynen (1993), Hodges (1996), and Rebonato (1999). The dynamic properties of the implied volatility time series is mainly analyzed using the Principal Component Analysis (PCA). In this context, a cross-section of the implied volatility surface in one direction is considered. If the cross-section is made on different points of the moneyness axis, then a series of term structure-curves is obtained. Analogously, if this is done on the time to expiration axis, a series of smile-curves is obtained. Then the PCA is applied. Examples of the term structure of at-the-money implied volatilities using the PCA can be found in Härdle and Schmidt (2000), Heynen et al. (1995), Zhu and Avellaneda (1997).
There are however some shortcomings with implied volatilities. There is considerable evidence that these volatilities are themselves stochastic. Typically the shape of the distribution (and hence the smile) is unstable because of 'volatility of volatility'. Another problem is that the asset returns and volatility may be correlated, but often non-linearly, usually reflected in fat-tailed and skewed distributions of the underlying asset. Implied volatilities can also be biased, especially if they are based upon options that are thinly traded.
XploRe
offers different algorithms to calculate implied
volatilities. Further on, the volatility surfaces can be
constructed through parametric or non-parametric approaches and
plotted. Fengler et al. (2001) analyze implied volatilities using
XploRe
as a computational tool, see e-book
Applied Quantitative Finance, ch.
7.
In practice several implied volatilities are obtained simultaneously from different options on the same stock and a composite implied volatility for the stock is then calculated by taking a suitably weighted average of the individual implied volatilities. Note, that XploRe computes only the implied volatilities from each option. If a composite implied volatility is required, the user then has to decide about the weighting scheme. It is however important that the weights reflect the sensitivity of the option prices to volatility, such as the price of the at-the-money option is far more sensitive to volatility than the price of the deep out-of-the-money option. Different weighting schemes are discussed in Latene and Rendelman (1976), by Chiras and Manaster (1978), and in Whaley (1982).
|
european
uses the quantlet
volatility
to compute
implied volatilites. Note, that the quantlet
optstart
is
not explicitly mentioned as it performs no calculation. It calls
either the quantlet
european
, or
american
to
compute implied volatilities for european and american options
respectively.
XploRe
does not recommend the calculation of
implied volatilities for American options valuated with the
MacMillan approximation method (see subsection 11.2.4).
ImplVola
offers two different algorithms to calculate
implied volatilities, the bisection and the Newton-Raphson. The
most widely used technique for the estimation of the implied
volatility is the Newton-Raphson iterative algorithm. It involves
making an initial guess as to the implied volatility of the
option. It then uses the Greek derivative of the option price
relative to changes in volatility (the vega) to make a new guess
if the initial guess is off the mark. Tompkinks (1994, pp. 143)
writes the algorithm as the following:
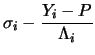 |
|||
The convergence to the correct answer is often achieved in only two or three iterations, if the option price relationship to time is continuous and relatively linear. This is the case for European vanilla options, where the price-volatility relationship is a smooth, relatively linear curve. For other kinds of options including American options, where a significant probability of early exercise exists, or for complex options, which have a kinked rather than a smooth price-volatility relationship, this technique may not work. For these types of options, the bisection method is then preferred. The bisection algorithm can be described as the following:
Step 1. Pick ![]() and
and ![]() so that
so that
Step 2. Choose
![]()
If
![]() then
then
![]() , else
, else
![]()
Step 2 is repeated until a sufficiently good approximation for
![]() is obtained.
is obtained.
In the following example
ImplVola
is used to calculate
implied volatilities for four different options (two calls and two
puts) on different underlying assets with the Newton-Raphson
algorithm:
The
XploRe
output shows the calculated implied volatilities:
Implied volatility for the first European call option is
![]() . For the same option, implied volatility is
. For the same option, implied volatility is
![]() when calculated with the quantlet
volatility
. The examples show that it makes no significant
difference if implied volatility is computed using
ImplVola
or
volatility
. The results differ only by
when calculated with the quantlet
volatility
. The examples show that it makes no significant
difference if implied volatility is computed using
ImplVola
or
volatility
. The results differ only by
![]() .
.
volatility
computes the implied volatility of each
european option as a result of an optimization process of the
option price along the volatility ![]() . It uses the function
nelmin
, which searches for a minimum of the squared option
price function. In each iteration step the function is evaluated
at a simplex of (p+1) points. The iteration stops when the
variance is less than a predetermined value or when a given
iteration number is reached. Technical details are given in
Nelder and Mead (1965).
. It uses the function
nelmin
, which searches for a minimum of the squared option
price function. In each iteration step the function is evaluated
at a simplex of (p+1) points. The iteration stops when the
variance is less than a predetermined value or when a given
iteration number is reached. Technical details are given in
Nelder and Mead (1965).
The input parameter
![]() in
volatility
is a scalar
that specifies the type of the dividend payment: for
in
volatility
is a scalar
that specifies the type of the dividend payment: for
![]() no dividend, for
no dividend, for
![]() a continuously paid dividend and
for
a continuously paid dividend and
for
![]() a fixed dividend at the end of T is assumed.
Finally, if
a fixed dividend at the end of T is assumed.
Finally, if
![]() , then an exchange rate is assumed as
underlying.
, then an exchange rate is assumed as
underlying.
The following example calculates the implied volatility for only one European call, when no dividends are assumed:
european
yields the
same result for implied volatility.
The output window yields:
It is possible to calculate simultaneously implied volatility for one or more options by specifying input parameters directly in
volatility(S,K,r,tau,opt,optprice,tyoeofdiv,div).
The usual practice to construct implied volatility surfaces for
arbitrary strikes ![]() and maturities
and maturities
![]() is to smooth
the discrete data. This can be done in a parametric or
non-parametric way. For example, it is common practice in many
banks, to use (piecewise) polynomial functions to fit the implied
volatility smile (Dumas et al.; 1996).
XploRe
offers the
following two quantlets to construct and plot volatility surfaces:
is to smooth
the discrete data. This can be done in a parametric or
non-parametric way. For example, it is common practice in many
banks, to use (piecewise) polynomial functions to fit the implied
volatility smile (Dumas et al.; 1996).
XploRe
offers the
following two quantlets to construct and plot volatility surfaces:
|
volsurf
computes the implied volatility surface using a
kernel smoothing procedure. Either a Nadaraya-Watson estimator or
a local polynomial regression is employed.
The local polynomial method is used to estimate an unknown
function ![]() , which expresses a functional dependence between an
explanatory variable
, which expresses a functional dependence between an
explanatory variable
![]() and the dependent
variable
and the dependent
variable
![]() . In contrast to the
parametric regression, there are no restrictions on the form of
. In contrast to the
parametric regression, there are no restrictions on the form of
![]() , i.e. theory does not state whether
, i.e. theory does not state whether ![]() is
linear, quadratic or increasing in
is
linear, quadratic or increasing in ![]() (Härdle et al.; 2001).
The local polynomial method is based on the idea that under
suitable conditions, the function
(Härdle et al.; 2001).
The local polynomial method is based on the idea that under
suitable conditions, the function ![]() can be locally, i.e. at an
observation point
can be locally, i.e. at an
observation point
![]() , approximated through a Taylor
expansion. The local polynomial can then be fitted by a weighted
least squared regression problem. Only the observations, which are
close enough to
, approximated through a Taylor
expansion. The local polynomial can then be fitted by a weighted
least squared regression problem. Only the observations, which are
close enough to
![]() have to be considered in the
minimization process. The neighborhood is realized by including
kernel weights into this process. In contrast to the parametric
least squares, the estimator varies with the observations
have to be considered in the
minimization process. The neighborhood is realized by including
kernel weights into this process. In contrast to the parametric
least squares, the estimator varies with the observations
![]() for
for
![]() . The whole surface is obtained
by running the above local polynomial regression for each
observation
. The whole surface is obtained
by running the above local polynomial regression for each
observation
![]() .
.
Alternatively,
volsurf
uses the filtered data set to
construct a smooth estimator of the implied volatility surface,
defined on a fixed grid, using the non-parametric Nadaraya-Watson
estimator. Given the exploratory variables
![]() ,
the two dimensional Nadaraya-Watson kernel estimator is
,
the two dimensional Nadaraya-Watson kernel estimator is
where
![]() is the implied volatility from the observed
option price,
is the implied volatility from the observed
option price, ![]() and
and ![]() are univariate kernel functions, and
are univariate kernel functions, and
![]() and
and ![]() are the bandwidths.
are the bandwidths.
volsurf
uses a quartic Kernel for both, the local
polynomial and the Nadaraya-Watson estimator. The order 2 quartic
kernel is given by
The choice of another kernel, for instant a Gaussian kernel as in
Cont and da Fonseca (2002), instead of quartic Kernel does not
influence the results very much. The important parameters are the
bandwidth parameters ![]() and
and ![]() which determine the degree of
smoothing. Too small values will lead to a bumpy surface, too
large ones will smooth away important details. Härdle (1994, ch.
5) and Härdle et al. (2001, ch. 4.3) discuss different
ways how to calculate the bandwidth, as for instance using a
cross-validation criterion, or an adaptive bandwidth estimator in
order to obtain an 'optimal' bandwidth.
which determine the degree of
smoothing. Too small values will lead to a bumpy surface, too
large ones will smooth away important details. Härdle (1994, ch.
5) and Härdle et al. (2001, ch. 4.3) discuss different
ways how to calculate the bandwidth, as for instance using a
cross-validation criterion, or an adaptive bandwidth estimator in
order to obtain an 'optimal' bandwidth.
The first input parameter ![]() in
volsurf
is a (n x 6)
dimensional data matrix. The columns one to six contain:
underlying asset prices
in
volsurf
is a (n x 6)
dimensional data matrix. The columns one to six contain:
underlying asset prices ![]() , strike prices
, strike prices ![]() , interest
rates
, interest
rates ![]() , time to expiration
, time to expiration
![]() , option prices and
types of option (1 for call and 0 for put). The next five input
parameters are concerned with the construction of the volatility
surface.
, option prices and
types of option (1 for call and 0 for put). The next five input
parameters are concerned with the construction of the volatility
surface.
![]() is a (2 x 1) dimensional vector, where
the first element refers to the strike dimension and the second to
time to expiration.
is a (2 x 1) dimensional vector, where
the first element refers to the strike dimension and the second to
time to expiration.
![]() (
(
![]() ) and
) and
![]() (
(
![]() ) are scalar constants giving the
lowest (highest) limit of the strike dimension and of time to
expiration in the volatility surface, respectively. The metric in
volsurf
is either moneyness
) are scalar constants giving the
lowest (highest) limit of the strike dimension and of time to
expiration in the volatility surface, respectively. The metric in
volsurf
is either moneyness ![]() (
(
![]() ), where
), where
![]() is the (implied) forward price of the underlying asset
computed as
is the (implied) forward price of the underlying asset
computed as
![]() , or is the original strike price
, or is the original strike price
![]() (
(
![]() ). The parameter
). The parameter
![]() is a (2 x 1)
dimensional vector determining the width of the bins for the
kernel estimator. The parameter
is a (2 x 1)
dimensional vector determining the width of the bins for the
kernel estimator. The parameter ![]() is a scalar, which
indicates whether the Nadaraya-Watson estimator (
is a scalar, which
indicates whether the Nadaraya-Watson estimator (![]() ) or
the local polynomial regression (
) or
the local polynomial regression (
![]() ) is used. The
last parameter,
) is used. The
last parameter,
![]() , is optional. As in quantlet
ImplVola
, if
, is optional. As in quantlet
ImplVola
, if
![]() then the bisection
method is used to compute implied volatilities. The default method
is the Newton-Raphson algorithm (see subsection 11.5.1).
then the bisection
method is used to compute implied volatilities. The default method
is the Newton-Raphson algorithm (see subsection 11.5.1).
The output of the quantlet
volsurf
consists of two
variables. The first one,
![]() , contains the co-ordinates
of the points computed for the volatility surface. It is a (N x 3)
dimensional matrix, where N is the number of grid points. The
second one,
, contains the co-ordinates
of the points computed for the volatility surface. It is a (N x 3)
dimensional matrix, where N is the number of grid points. The
second one,
![]() , is a (M x 3) dimensional matrix,
which contains the co-ordinates of the M options used to estimate
the surface. In both variables, the columns one to three contain
the values of strike dimension, of time to expiration and of
estimated implied volatility, respectively.
, is a (M x 3) dimensional matrix,
which contains the co-ordinates of the M options used to estimate
the surface. In both variables, the columns one to three contain
the values of strike dimension, of time to expiration and of
estimated implied volatility, respectively.
volsurfplot
is a graphical tool used to display the
volatility surface constructed with the quantlet
volsurf
.
Therefore the input parameters are the co-ordinates of the
volatility surface
![]() and of the original option values
contained in
and of the original option values
contained in
![]() , which were used in
volsurf
to construct the surface. The third input parameter
, which were used in
volsurf
to construct the surface. The third input parameter
![]() is optional. It determines, whether the
graph-limits are based on the original option observations stored
in
is optional. It determines, whether the
graph-limits are based on the original option observations stored
in
![]() , or based on coordinates of estimated surface
, or based on coordinates of estimated surface
![]() . By default
. By default
![]() , the graph is
adjusted according to the estimated surface.
, the graph is
adjusted according to the estimated surface.
To illustrate, two examples as given in the description part of
volsurf
are used. The first example constructs the
volatility surface in moneyness metric (
![]() ), using
the Nadaraya-Watson estimator (
), using
the Nadaraya-Watson estimator (
![]() ). The implied
volatilities are computed with the bisection method
). The implied
volatilities are computed with the bisection method
(
![]() ).
).
volsurfplot
displays the implied volatility surface as a
function of moneyness and time to expiration in years
(Figure 11.22). The original options are marked red.
The graph shows a decreasing profile in moneyness ('skew') and
changes in the volatility term structure. The 'skew' is the degree
of asymmetry on upper and lower sides of the underlying
distribution.
A second example constructs the volatility surface also using the
default Nadaraya-Watson estimator (![]() ), but in strike
metric (
), but in strike
metric (
![]() ), for the same data set as in the previous
example. The implied volatilities are now computed with the
default Newton-Raphson algorithm.
), for the same data set as in the previous
example. The implied volatilities are now computed with the
default Newton-Raphson algorithm.
volsurfplot
displays the implied volatility surface as a
function of strike price and of time to expiration in years
(Figure 11.23). The slight difference between the two
surfaces relates to the different algorithms used for computing
the implied volatilities. However, the profile in strike is mainly
downward sloping and the profile in maturity shows a variable
volatility term structure. Both examples confirm the well-known
evidence that the implied volatility surface is other than flat,
which would be the case if the assumption of constant volatility
in the Black-Scholes model was correct.
The variation of implied Black-Schloles volatilities, with both strike and expiration is currently a persistent feature of option markets. Jarrow and Rudd (1982) argue that the smile for a given maturity can be partially explained by departures from lognormality in underlying asset prices, particulary for out-of-the-money options. Researchers have attempted to enrich the Black-Scholes model to account for the smile. Extensions, such as jumps in the underling asset price (see subsection 11.1.2) or stochastic volatility factor (Hull and White; 1987), unfortunately cause several practical difficulties, for example the violation of the risk-neutral condition (Härdle and Zheng; 2001).
Implied binomial trees (IBT) proposed by Derman and Kani (1994), Dupire (1994), Rubinstein (1994), Barle and Cakici (1998) account for risk-neutrality and extend the Black-Scholes theory, making it consistent with the shape of the smile. This consistency is achieved by extracting the implied evolution of the stock price from the market prices of liquid European vanilla options on the underlying stock.
CRR is a binomial tree, which is a discrete version of the geometric Brownian motion (11.4). Similarly, IBT and any other multinomial tree can be viewed as discrete versions of the following diffusion process of the underlying asset:
The variable ![]() is the risk-neutral drift and
is the risk-neutral drift and
![]() is the instantaneous local volatility function, which is dependent
on both underlying price and time. Models of this type usually
involve a special parametric form of
is the instantaneous local volatility function, which is dependent
on both underlying price and time. Models of this type usually
involve a special parametric form of
![]() . In contrast,
the IBT approach deduces
. In contrast,
the IBT approach deduces
![]() numerically from the
smile. It ensures that local volatility varies from node to node,
so that the market price of any plain vanilla option can be
matched. Option prices for all strikes and expirations, obtained
by interpolation from known option prices, will determine the
position and the probability of reaching each node in the implied
tree (Derman and Kani; 1994). The standard (CRR) binomial tree
Figure (11.4) is then replaced by a distorted or implied
tree as in Figure (11.24).
numerically from the
smile. It ensures that local volatility varies from node to node,
so that the market price of any plain vanilla option can be
matched. Option prices for all strikes and expirations, obtained
by interpolation from known option prices, will determine the
position and the probability of reaching each node in the implied
tree (Derman and Kani; 1994). The standard (CRR) binomial tree
Figure (11.4) is then replaced by a distorted or implied
tree as in Figure (11.24).
The IBT and any other implied tree should satisfy the following conditions:
When constructing an implied binomial tree, (see subsection 11.5.2) there is only one free parameter, which allows an arbitrary choice for the central node at each level of the tree. In a continuous limit, where there are an infinite number of nodes at each time step, this choice becomes irrelevant. Consequently, there is a unique implied binomial tree that fits option prices in any market. This feature can be disadvantageous, because there is no room for adjustment by inconsistency and/or arbitrage, or by implausible local volatility and probability distribution. One possible solution is to make the structure of the implied tree more flexible by using implied trinomial trees (see subsection 11.5.3).
XploRe
offers the possibility to generate the IBT by using
either the quantlet
IBTdk
, which is based on the
Derman and Kani (1994) method, or the quantlet
IBTbc
based on the Barle and Cakici (1998) method:
|
In
IBTdk
and
IBTbc
, the input
parameter ![]() stands for the underlying asset price,
stands for the underlying asset price, ![]() for the continuously compounded risk-free interest rate,
for the continuously compounded risk-free interest rate,
![]() for the number of time steps and
for the number of time steps and
![]() for
time to expiration. The last parameter
for
time to expiration. The last parameter
![]() is a
string, specifying the name of the function used to define how the
Black-Scholes implied volatilities change with strike and
expiration.
is a
string, specifying the name of the function used to define how the
Black-Scholes implied volatilities change with strike and
expiration.
Both quantlets
IBTdk
and
IBTbc
output the
tree of underlying asset prices, contained in a
![]() dimensional matrix, the tree of transition probabilities contained
in a
dimensional matrix, the tree of transition probabilities contained
in a
![]() dimensional matrix and the tree of Arrow-Debreu
prices contained in a
dimensional matrix and the tree of Arrow-Debreu
prices contained in a
![]() dimensional matrix.
dimensional matrix.
The following example illustrates how to generate an IBT using the
Derman and Kani method. The Black-Scholes implied volatility is
assumed to be a linear function of ![]() . The IBT corresponds
to
. The IBT corresponds
to ![]() year and
year and
![]() year.
year.
The output shows the one year stock price implied binomial tree
ibtree.Tree, the transition probability tree
ibtree.prob and the Arrow-Debreu price tree
ibtree.lb. The elements at the ![]() th column of the
th column of the
ibtree.Tree matrix correspond to the stock prices at the
level ![]() of the tree. The element
of the tree. The element ![]() of the
of the ![]() th column
and
th column
and ![]() th row of the
th row of the ibtree.prob matrix corresponds to the
transition probability of moving from node ![]() to node
to node
![]() . Using the Arrow-Debreu prices from the
. Using the Arrow-Debreu prices from the
ibtree.lb matrix together with the stock price at
respective nodes, a discrete approximation of the implied
distribution of the stock prices can be obtained.
The quantlet
IBTlocsigma
needs the following parameters to
compute the implied local volatilities in each node of the tree:
![]() - the stock prices of the nodes generated by IBTdk or
IBTbc,
- the stock prices of the nodes generated by IBTdk or
IBTbc,
![]() - the transition probability tree,
- the transition probability tree, ![]() -
the highest desired level,
-
the highest desired level,
![]() - the annualized length
of one time step. The output is a 3 column matrix, which consists
of: i) the stock price at some nodes of the implied binomial tree,
ii) time to expiration, and iii) the estimated implied local
volatility at these nodes.
- the annualized length
of one time step. The output is a 3 column matrix, which consists
of: i) the stock price at some nodes of the implied binomial tree,
ii) time to expiration, and iii) the estimated implied local
volatility at these nodes.
The quantlet
IBTvolaplot
plots the implied volatility in
the implied binomial tree as a function of strike and time to
expiration. The following input parameters are required:
![]() - implied local volatilities computed through
IBTlocsigma
,
- implied local volatilities computed through
IBTlocsigma
,
![]() - the bandwidth of the time
interval,
- the bandwidth of the time
interval,
![]() and
and
![]() - the lowest and
the highest strike dimensions of the volatility surface,
- the lowest and
the highest strike dimensions of the volatility surface, ![]() - the number of steps to be estimated.
- the number of steps to be estimated.
The following example fits an implied five-year tree with 20
levels. The implied local volatility
![]() in the
implied tree at different time to expirations and stock price
levels is presented in Figure (11.25). The plot confirms
the expected result, that the implied local volatility decreases
with stock price and increases with time to expiration.
in the
implied tree at different time to expirations and stock price
levels is presented in Figure (11.25). The plot confirms
the expected result, that the implied local volatility decreases
with stock price and increases with time to expiration.
The Barle and Cakici (1998) method can be used in exactly the same
way as the Derman and Kani (1994) method. The following output
shows the one year stock price tree, the transition probability
tree and the tree of Arrow-Debreu prices, when as in the above
example, the quantlet
IBTdk
is replaced by
IBTbc
and all other parameters remain the same. The
local volatility generated by Barle and Cakici IBT is plotted in
Figure (11.26).
Within an implied binomial tree framework, stock prices, transition probabilities, and Arrow Debreu prices at each node are calculated iteratively level by level. The following describes the construction of implied binomial trees using the Derman and Kani (1994) approach.
Assuming that ![]() levels of the tree have already been
constructed, the following explains the construction of the next
level,
levels of the tree have already been
constructed, the following explains the construction of the next
level, ![]() , of the implied binomial tree, which is illustrated
in Figure 11.27. The node
, of the implied binomial tree, which is illustrated
in Figure 11.27. The node ![]() , for
, for ![]() , at level
, at level ![]() of the implied tree is denoted with
of the implied tree is denoted with ![]() . As in the case of the
regular binomial tree, the asset price
. As in the case of the
regular binomial tree, the asset price ![]() in node
in node ![]() at time
at time ![]() , can either branch upwards to the node
, can either branch upwards to the node ![]() with
the stock price
with
the stock price
![]() , or downwards to the node i with the
stock price
, or downwards to the node i with the
stock price ![]() moving from level
moving from level ![]() to level
to level ![]() of
the tree.
of
the tree.
The Arrow-Debreu price at node ![]() , denoted as
, denoted as
![]() (Figure 11.27), is the price of an option that pays one
unit payoff in one and only one state
(Figure 11.27), is the price of an option that pays one
unit payoff in one and only one state ![]() at level
at level ![]() , otherwise
it pays zero. The Arrow-Debreu price is computed by forward
induction, as the sum over all paths, from the root of the tree to
node
, otherwise
it pays zero. The Arrow-Debreu price is computed by forward
induction, as the sum over all paths, from the root of the tree to
node ![]() , of the product of transition probabilities at each
node, in each path, leading to node
, of the product of transition probabilities at each
node, in each path, leading to node ![]() , discounted with the
risk-free interest rate.
, discounted with the
risk-free interest rate.
The next step involves:
The tree is also constructed to insure that ![]() independent
European vanilla options -
independent
European vanilla options -
![]() for call and
for call and
![]() for put - with strike
for put - with strike ![]() and expiring at
time
and expiring at
time ![]() are priced correctly, i.e. the theoretical values
of these options should match their market prices (Derman and Kani; 1994),
which uses an additional
are priced correctly, i.e. the theoretical values
of these options should match their market prices (Derman and Kani; 1994),
which uses an additional ![]() degrees of freedom. The theoretical
binomial value of any option with strike
degrees of freedom. The theoretical
binomial value of any option with strike ![]() and expiration at
and expiration at
![]() , is the sum over all nodes
, is the sum over all nodes ![]() at the
at the ![]() th level,
of the transition probabilities of reaching each node
th level,
of the transition probabilities of reaching each node ![]() multiplied by the payoff there and discounted with the risk-free
interest rate:
multiplied by the payoff there and discounted with the risk-free
interest rate:
This construction leads to ![]() equations:
equations: ![]() for the expected
value of the underlying as in (11.69) and
for the expected
value of the underlying as in (11.69) and ![]() for the
option prices as in (11.70) and (11.71). There
are
for the
option prices as in (11.70) and (11.71). There
are ![]() unknowns: (n+1) stock prices in nodes at level (n+1) of
the tree and n transition probabilities. Hence, there is only one
degree of freedom left, which is used to ensure that the center
node in level
unknowns: (n+1) stock prices in nodes at level (n+1) of
the tree and n transition probabilities. Hence, there is only one
degree of freedom left, which is used to ensure that the center
node in level ![]() equals the current underlying price. Solving the
equations, the tree is advanced only by one time step. The ITB is
constructed by repeating this procedure for each time step. Then
all stock prices, transition probabilities and Arrow-Debreu prices
at any node in the tree will be known.
equals the current underlying price. Solving the
equations, the tree is advanced only by one time step. The ITB is
constructed by repeating this procedure for each time step. Then
all stock prices, transition probabilities and Arrow-Debreu prices
at any node in the tree will be known.
The implied local volatility
![]() that describes the structure of the second moment of the
underlying process at any level
that describes the structure of the second moment of the
underlying process at any level ![]() of the tree can then be
calculated as a discrete approximation of the following
conditional variance
of the tree can then be
calculated as a discrete approximation of the following
conditional variance
One problem with this approach, is that negative probabilities sometimes arise. When a particular probability turns out to be negative, it is necessary to introduce a rule to override the option price responsible for this negative probability. Another shortcoming is that calculating interpolated option prices by the CRR is computationally intensive.
Barle and Cakici (1998) proposed an improvement on the Derman and Kani (1994) algorithm. The major modification is that for the choice of the central node, their algorithm takes the risk-free interest rate into account. A detailed explanation of the Barle and Cakici (1998) algorithm can be found in Härdle and Zheng (2001).
Implied tree models account for the volatility smile and attempt
to price options consistent with the market price. They can be
constructed in various ways. Implied binomial trees as discussed
in subsection (11.5.2) have just enough parameters, node
prices and transition probabilities to fit the smile. In contrast,
a trinomial tree has by construction more parameters, since within
one single node the stock price can move to one of three possible
future values, each with its own respective probability
(Figure 11.28). For example at node ![]() , at time
, at time ![]() ,
there are five unknown parameters: two transition probabilities
,
there are five unknown parameters: two transition probabilities
![]() ,
, ![]() and three new node prices
and three new node prices ![]() ,
, ![]() ,
and
,
and ![]() .
.
In a risk-neutral trinomial tree, there are two constrains
concerning the expected value and the variability of the stock
price for these five unknown parameters (Derman, Kani and Chriss; 1996).
Consequently, there are three degrees of freedom, which can be
used to freely specify three of the parameters, ![]() ,
, ![]() ,
and
,
and ![]() , required to fix the tree. No unique trinomial tree,
but many equivalent trinomial trees exist, which as
, required to fix the tree. No unique trinomial tree,
but many equivalent trinomial trees exist, which as ![]() goes to zero represent the same continuous theory.
goes to zero represent the same continuous theory.
The three degrees of freedom can be used to conveniently specify the state space - the underlying price in every node - and allow the transition probabilities to vary as smoothly as possible across the tree. In other words, there is total freedom over the choice of the state space of an implied trinomial tree. This flexibility is a major advantage of using trinomial trees.
A standard trinomial tree represents a constant volatility world and is constructed out of a regular mesh (Figure 11.29). An implied trinomial tree has an irregular mesh, confirming the variation of local volatility with level and time across the tree (Figure 11.30).
An implied trinomial tree is usually constructed by two steps (Derman, Kani and Chriss; 1996). In the first step, the initial state space is selected. When implied volatility varies slowly with strike and expiration, a constant volatility trinomial tree can be used. This can be done by combining the two steps of the CRR binomial tree into a single step of a trinomial tree as illustrated in Figure (11.31). Other methods used to build a constant volatility trinomial tree are presented in Derman, Kani and Chriss (1996). If volatility varies significantly with strike and expiration, a trinomial space with proper skew and term structure must be chosen.
By knowing the location of every node, the market forwards and option prices are used in the second step to fix transition probabilities. This is done iteratively to ensure that all European vanilla options will have theoretical values that match their market prices.
Constructing the tree may result in transition probabilities being negative or greater than one, which is inconsistent with rational option prices and allows arbitrage. In this case, a rule must be defined for overwriting the option price which produces incorrect probabilities.
Komorád (2002) explains in detail how to use XploRe for constructing implied trinomial trees. Since this is included in Tutorials-Finance in XploRe , these quantlets are introduced briefly.
ITT
is used to compute the state space of an implied tree,
the probability matrices, the Arrow-Debreu prices and the local
volatility matrix. It uses the quantlet
ITTcrr
to compute
the option prices.
ITTcrr
builds up a constant volatility
trinomial tree by combining two steps of a CRR binomial tree.
The simplest way to display results is to apply the quantlet
plotITT
. Once the ITT is constructed,
plotITT
offers the possibility to plot the state space of the ITT, the
tree of transition probabilities, the tree of local volatilities,
the tree of Arrow Debreu prices and the state price density.
More advanced features allow the user to integrate the plot of any
trinomial tree with other graphical objects, into one graph.
grITTstsp
returns the state space of an implied trinomial
tree with transition probabilities as a graphical object
(Komorád; 2002), whereas
grITTspd
generates a state price
density of an implied trinomial tree (see Komorád (2002) for a
detailed explanation and examples).
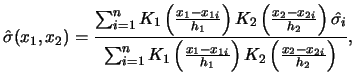
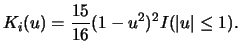
![\includegraphics[width=1.3\defpicwidth]{volsurfNW-BS.ps}](xlghtmlimg1304.gif)

![\includegraphics[width=1.3\defpicwidth]{volsurfNW-NR.ps}](xlghtmlimg1306.gif)

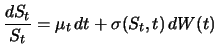
![\includegraphics[width=0.8\defpicwidth]{IBT3.ps}](xlghtmlimg1310.gif)
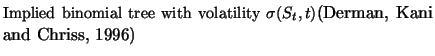
![\includegraphics[width=1.5\defpicwidth]{IBTvola.ps}](xlghtmlimg1330.gif)

![\includegraphics[width=1.5\defpicwidth]{IBTvolabc.ps}](xlghtmlimg1332.gif)

![\includegraphics[width=1\defpicwidth]{IBTn2-n+1.ps}](xlghtmlimg1340.gif)
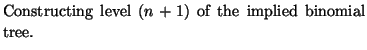
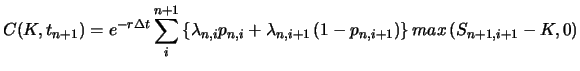
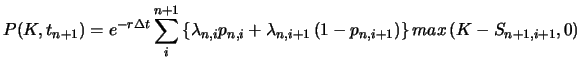
![\includegraphics[width=0.45\defpicwidth]{trin-1sch.ps}](xlghtmlimg1366.gif)

![% latex2html id marker 56022
$\textstyle \parbox{6.2cm}{
\ \includegraphics[widt...
...picwidth]{TT.ps}
\ \caption{\small Standard trinomial tree.}\cite{de:ka:ch:96}}$](xlghtmlimg1367.gif)
![% latex2html id marker 56023
$\textstyle \parbox{6.1cm}{
\ \includegraphics[widt...
...fpicwidth]{ITT.ps}
\caption{\small Implied trinomial tree.}\cite{de:ka:ch:96}}$](xlghtmlimg1368.gif)
![\includegraphics[width=0.5\defpicwidth]{TTT-CV.ps}](xlghtmlimg1370.gif)